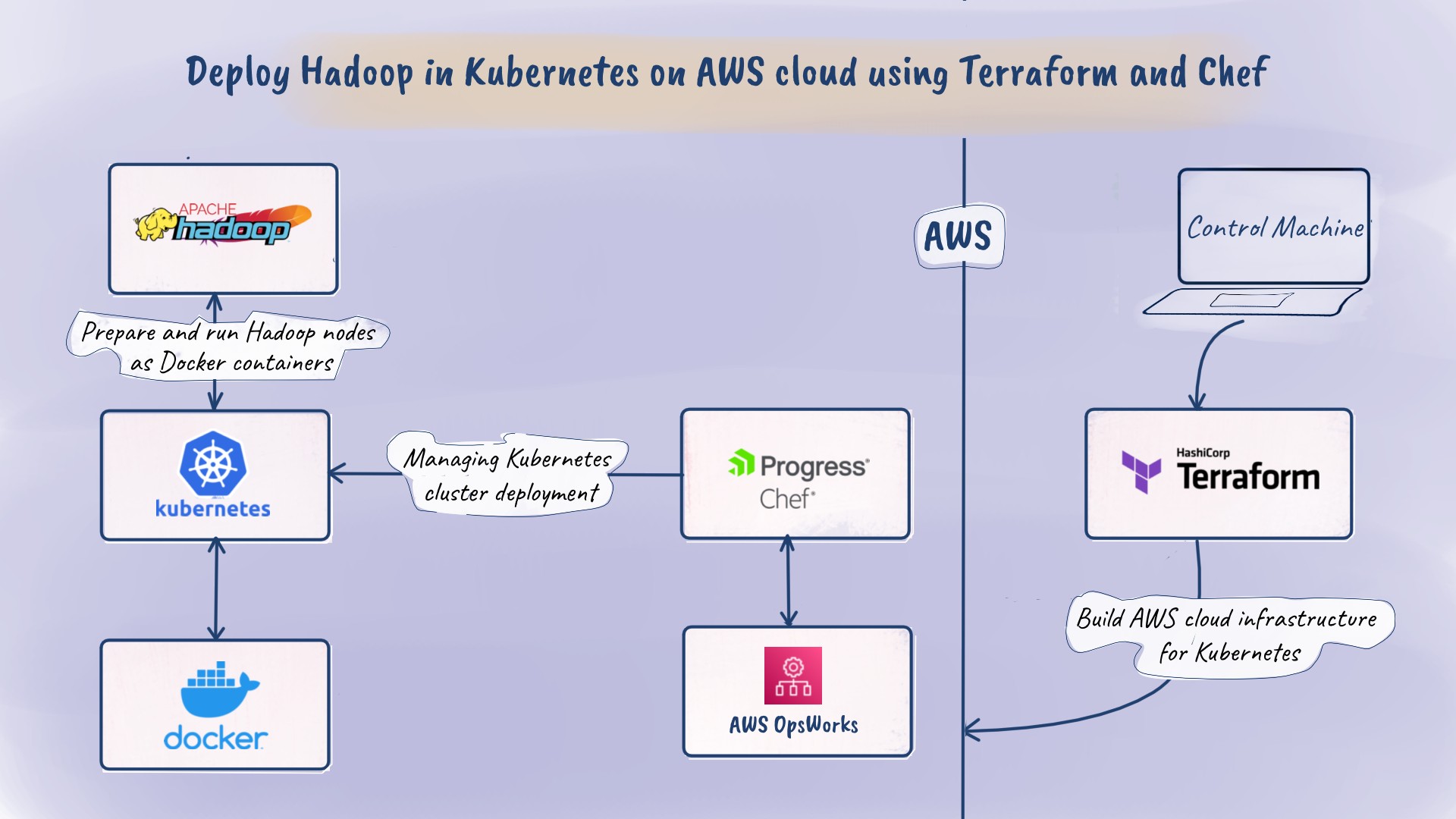
Hello, welcome to our SloopStash blog. In this post, we want to demonstrate how to build a Hadoop cluster within a self-managed Kubernetes running on the AWS cloud infrastructure. It is easy to try this hands-on if you have an AWS account. For simplicity, we have divided the hands-on into three major sections as listed below.
- Managing AWS cloud infrastructure for Kubernetes using Terraform.
- Managing Kubernetes cluster deployment on AWS OpsWorks using Chef.
- Running Hadoop nodes as Docker containers on Kubernetes cluster.
Let’s try to understand the architecture of the self-managed Kubernetes cluster running on the AWS cloud infrastructure. We need an Amazon VPC network with public and private subnets. The Kubernetes nodes run within Amazon EC2 instances on private VPC subnets, and the NAT Amazon EC2 instances run within public VPC subnets. We use AWS OpsWorks for managing Kubernetes nodes as Amazon EC2 instances. We need an Amazon S3 bucket for storing the Chef cookbooks and the Chef cookbooks are used to deploy Docker, Kubernetes services on Amazon EC2 instances. Here is the list of prerequisites that are needed to get started with the hands-on.
- An AWS account
- Credential of an AWS IAM user with administrator access
- A Linux Ubuntu 18.04 LTS machine
First, we need to download the Kubernetes starter-kit from the SloopStash GitHub account. The Kubernetes starter-kit contains all code, configuration, and technical things required to build and run a self-managed Kubernetes cluster on AWS cloud infrastructure.
# Install Git.
$ sudo apt install git
# Download Kubernetes starter-kit from GitHub to local filesystem path.
$ sudo git clone -b v2.1.1 https://github.com/sloopstash/kickstart-kubernetes.git /opt/kickstart-kubernetes
# Change ownership of Kubernetes starter-kit directory.
$ sudo chown -R $USER:$USER /opt/kickstart-kubernetes
Managing AWS cloud infrastructure for Kubernetes using Terraform
Here, we use Terraform to automate the build of AWS cloud infrastructure, which is needed to deploy and run a self-managed Kubernetes cluster. The first step is to install Terraform on our Linux Ubuntu 18.04 LTS machine. Then, build/provision the AWS cloud infrastructure required for running the Kubernetes cluster.
Install Terraform CLI on Linux Ubuntu 18.04 LTS machine
To install Terraform, we need to download its release archive and extract the executable binary for Linux. This is the preferred way of installing Terraform on a Linux-based operating system. No matter how we install Terraform, it’s just an executable binary. Once the installation is completed, we need to check Terraform version to verify successful installation.
# Download Terraform.
$ wget https://releases.hashicorp.com/terraform/1.0.1/terraform_1.0.1_linux_amd64.zip -P /tmp
# Extract Terraform from archive.
$ unzip /tmp/terraform_1.0.1_linux_amd64.zip
# Install Terraform.
$ sudo mv terraform /usr/local/bin
# Check Terraform version.
$ terraform --version
Build AWS cloud infrastructure for Kubernetes using Terraform
We have organized the Terraform configuration as modules to extend and reuse it easily. In this place, we execute our Terraform configuration to build/provision resources on the AWS cloud, specifically AWS IAM, Amazon VPC, Amazon S3, Amazon EC2, and AWS OpsWorks.
First, we initialize Terraform to install the providers and plugins referenced in the Terraform configuration. Second, we need to generate a plan from Terraform configuration. Third, we have to execute the plan to build/provision the AWS resources required for running the self-managed Kubernetes cluster. Once the Terraform plan is executed successfully, then we need to verify the resources it created on the AWS cloud.
- Make sure to give your mobile number as Amazon S3 bucket prefix when Terraform prompts for input.
- Save the Terraform output to a text file, as it contains the Amazon S3 bucket name (which we use for storing Chef cookbooks) and public IP of NAT Amazon EC2 instance (which we also use as SSH bastion host).
# Switch to Kubernetes starter-kit directory.
$ cd /opt/kickstart-kubernetes/terraform
# Configure AWS IAM user credential.
$ export AWS_ACCESS_KEY_ID="<AWS_ACCESS_KEY_ID>"
$ export AWS_SECRET_ACCESS_KEY="<AWS_SECRET_ACCESS_KEY>"
# Create SSH key pair to authenticate SSH server running on Amazon EC2 instances.
$ ssh-keygen -t rsa -f ../secret/node -N ''
# Initialize Terraform configuration.
$ terraform init
# Create Terraform workspace.
$ terraform workspace new cmn
# Generate Terraform plan.
$ source conf/cmn.env
$ terraform plan -var-file conf/cmn.tfvars -out conf/cmn.tfplan
# Apply Terraform plan.
$ terraform apply conf/cmn.tfplan
Managing Kubernetes cluster deployment on AWS OpsWorks using Chef
AWS OpsWorks is useful for managing, scaling Amazon EC2 instances. With AWS OpsWorks, we can perform Chef-based deployment on Amazon EC2 instances. AWS OpsWorks follows a contextual hierarchy structure, namely, stacks, layers, instances, and deployments. For better understanding, assume your software services as a stack, and layers are the abstraction of the services used in your software stack such as app, database, HTTP server, etc. Here, we will manage Kubernetes nodes as Amazon EC2 instances under the AWS OpsWorks layer.
Here, we use Chef to deploy the Kubernetes nodes on Amazon EC2 instances running within an AWS OpsWorks stack. We have written Chef cookbooks for deploying the master and worker nodes to form a Kubernetes cluster. For that purpose, we configured the AWS OpsWorks layer with Chef cookbook recipes that can install, configure, manage Docker and Kubernetes services on the Amazon EC2 instances.
Upload Chef cookbooks to Amazon S3 bucket
Now, we have to archive and upload the Chef cookbooks to the Amazon S3 bucket which was created during the Terraform run. Any Amazon EC2 instance we launch from within the AWS OpsWorks layer will automatically download and execute the Chef cookbooks to deploy Docker, Kubernetes services in the machine.
# Switch to Kubernetes starter-kit directory.
$ cd /opt/kickstart-kubernetes/chef
# Archive Chef cookbooks.
$ tar czf cookbooks.tar.gz cookbook
# Upload Chef cookbooks to Amazon S3 bucket.
$ aws s3 mv cookbooks.tar.gz s3://<AMAZON_S3_BUCKET_NAME>/cookbooks.tar.gz --region us-west-2
Add Amazon EC2 instances to AWS OpsWorks layer
Here, we add blueprints of Amazon EC2 instances within an AWS OpsWorks layer. Actual Amazon EC2 instances are booted only if, we click and start the blueprints within the AWS OpsWorks layer. Go to the AWS OpsWorks service dashboard and navigate to the Stacks listing view. Choose osw-kubernetes-stk AWS OpsWorks stack and then select Instances tab. Finally, add blueprints of Amazon EC2 instances under osw-kubernetes-1-lr AWS OpsWorks layer.
# Launch Amazon EC2 instance for master Kubernetes node 1.
Hostname: osw-kubernetes-1-mtr-1
Size: t3a.small
Subnet: vpc-kubernetes-sn-2
Scaling type: 24/7
SSH key: ec2-key-pair
Operating system: Amazon Linux 2
OpsWorks Agent version: Inherit from stack
Tenancy: Default - Rely on VPC settings
Root device type: EBS backed
Volume type: General Purpose SSD (gp2)
Volume size: 8
# Launch Amazon EC2 instance for worker Kubernetes node 1.
Hostname: osw-kubernetes-1-wkr-1
Size: t3a.small
Subnet: vpc-kubernetes-sn-1
Scaling type: 24/7
SSH key: ec2-key-pair
Operating system: Amazon Linux 2
OpsWorks Agent version: Inherit from stack
Tenancy: Default - Rely on VPC settings
Root device type: EBS backed
Volume type: General Purpose SSD (gp2)
Volume size: 8
# Launch Amazon EC2 instance for worker Kubernetes node 2.
Hostname: osw-kubernetes-1-wkr-2
Size: t3a.small
Subnet: vpc-kubernetes-sn-1
Scaling type: 24/7
SSH key: ec2-key-pair
Operating system: Amazon Linux 2
OpsWorks Agent version: Inherit from stack
Tenancy: Default - Rely on VPC settings
Root device type: EBS backed
Volume type: General Purpose SSD (gp2)
Volume size: 8
Deploy master Kubernetes node on AWS OpsWorks layer using Chef
Let’s deploy Docker and Kubernetes services required to run the master Kubernetes node in Amazon EC2 instance within an AWS OpsWorks layer. Go to the AWS OpsWorks service dashboard and navigate to the Stacks listing view. Choose osw-kubernetes-stk AWS OpsWorks stack and then select Instances tab. Finally, boot Amazon EC2 instances under osw-kubernetes-1-lr AWS OpsWorks layer. Once the master Kubernetes node is successfully deployed, you need to SSH to it and create a bootstrap token to join worker Kubernetes nodes.
# Switch to Kubernetes starter-kit directory.
$ cd /opt/kickstart-kubernetes
# SSH to NAT Amazon EC2 instance.
$ ssh-add secret/node
$ ssh -A ec2-user@<NAT_SERVER_PUBLIC_IP>
# SSH to master Kubernetes node.
$ ssh ec2-user@<KUBERNETES_MASTER_NODE_PRIVATE_IP>
# List Kubernetes nodes.
$ kubectl get nodes -o wide --show-labels=false
# Create token in Kubernetes cluster.
$ sudo kubeadm token create --print-join-command
Add Kubernetes token to AWS OpsWorks layer settings
Here, we add a Kubernetes token to the settings section of the AWS OpsWorks layer. This token is needed to join worker Kubernetes nodes to the master nodes. Go to the AWS OpsWorks service dashboard and navigate to the Stacks listing view. Choose osw-kubernetes-stk AWS OpsWorks stack and then select Layers tab. Finally, choose osw-kubernetes-1-lr AWS OpsWorks layer and add Kubernetes token under it’s settings.
{
"kubernetes":{
"cluster":1,
"master":{
"ip_address":"<KUBERNETES_MASTER_NODE_PRIVATE_IP>"
},
"token":"<KUBERNETES_TOKEN>",
"token_hash":"<KUBERNETES_TOKEN_HASH>"
}
}
Deploy worker Kubernetes nodes on AWS OpsWorks layer using Chef
Let’s deploy Docker and Kubernetes services required to run the worker Kubernetes nodes in Amazon EC2 instances within an AWS OpsWorks layer. Go to the AWS OpsWorks service dashboard and navigate to the Stacks listing view. Choose osw-kubernetes-stk AWS OpsWorks stack and then select Instances tab. Finally, boot Amazon EC2 instances under osw-kubernetes-1-lr AWS OpsWorks layer. Once the worker Kubernetes nodes are successfully deployed, you need to SSH to the master Kubernetes node and verify if it joined the cluster properly.
# Switch to Kubernetes starter-kit directory.
$ cd /opt/kickstart-kubernetes
# SSH to NAT Amazon EC2 instance.
$ ssh-add secret/node
$ ssh -A ec2-user@<NAT_SERVER_PUBLIC_IP>
# SSH to master Kubernetes node.
$ ssh ec2-user@<KUBERNETES_MASTER_NODE_PRIVATE_IP>
# List Kubernetes nodes.
$ kubectl get nodes -o wide --show-labels=false
Prepare Hadoop cluster environment for Kubernetes using Chef
Finally, we need to create filesystem paths that are exposed as persistent Kubernetes volumes. Later on, these Kubernetes volumes are consumed by Hadoop nodes running as Docker containers within the Kubernetes cluster. Go to the AWS OpsWorks service dashboard and navigate to the Stacks listing view. Choose osw-kubernetes-stk AWS OpsWorks stack and then select Deployments tab. Finally, select Run Command to execute Chef recipes.
Settings:
Command: Execute Recipes
Recipes to execute: kubernetes::hadoop
Instances:
Select all: true
Running Hadoop nodes as Docker containers on Kubernetes cluster
For high level understanding, Hadoop is a Big Data framework to store and process humongous data. Hadoop framework/ecosystem has multiple components such as HDFS, YARN, MapReduce, etc. Generally, a Hadoop HDFS cluster is composed of master and slave nodes, where the name node is the master node and the data node is the slave node.
Our Hadoop HDFS cluster architecture has one name node and three data nodes. Here, we run the Hadoop nodes as Docker containers in the self-managed Kubernetes cluster we built. We use Kubernetes stateful-set to create and run Hadoop nodes as pods. For effective service discovery, the master and slave Hadoop nodes are exposed as Kubernetes services. The persistent Kubernetes volumes serve as the storage layer for Hadoop nodes running as pods.
# Switch to Kubernetes starter-kit directory.
$ cd /opt/kickstart-kubernetes
# SSH to NAT Amazon EC2 instance.
$ ssh-add secret/node
$ ssh -A ec2-user@<NAT_SERVER_PUBLIC_IP>
# SSH to master Kubernetes node.
$ ssh ec2-user@<KUBERNETES_MASTER_NODE_PRIVATE_IP>
# Switch to Hadoop starter-kit directory.
$ cd /opt/kickstart-hadoop
# Create Kubernetes volume.
$ kubectl apply -f kubernetes/volume/hadoop.yml
# Create Kubernetes namespace.
$ kubectl create namespace stg
# Create Kubernetes service.
$ kubectl apply -f kubernetes/service/hadoop.yml -n stg
# Create Kubernetes stateful-set.
$ kubectl apply -f kubernetes/stateful-set/hadoop/master.yml -n stg
$ kubectl apply -f kubernetes/stateful-set/hadoop/slave.yml -n stg
# List Kubernetes objects.
$ kubectl get nodes,persistentvolumes,namespaces,services,pods,persistentvolumeclaims -o wide -n stg
# Access Bash shell of a container running in Kubernetes pod.
$ kubectl exec -it -n stg pod/hadoop-master-node-0 -c main -- /bin/bash
$ su - hadoop
$ export JAVA_HOME=/usr/java/jdk1.8.0_131/jre
$ hdfs dfsadmin -report
$ hdfs dfs -mkdir -p /nginx/access/log
$ touch 20-07.2021.log
$ hdfs dfs -put -f 20-07.2021.log /nginx/access/log
$ hdfs dfs -ls -R /
$ exit
Hope it helps. Thank you.