Hello, and welcome back to the SloopStash blog! We are excited to have you here! Before we begin this blog post, we kindly ask that you have a basic understanding of either Apache Hadoop or Kubernetes. If you are not familiar with at least one of these topics, you may find this blog post less helpful.
Before getting started, it’s important to highlight that we are working towards production-like deployment of an Apache Hadoop multi-node cluster within a multi-node Kubernetes cluster. This setup enables us to scale effectively, whether in cloud or on-premise infrastructure, by properly configuring both Kubernetes and Hadoop.
The main takeaway is that you can implement this highly customizable Hadoop cluster within a Kubernetes cluster, which can run in a local developer machine with on-premise VMs or cloud infrastructure services such as Amazon EC2, Amazon EKS, Azure VM, Azure Kubernetes Service (AKS), Google Compute Engine, or Google Kubernetes Engine (GKE).
Deploy Kubernetes cluster in cloud or on-premise
To run any containerized application workloads at scale, you need a multi-node Kubernetes cluster, whether it is hosted in the cloud or on-premise infrastructure.
If you can deploy and run a cloud-based Kubernetes cluster on AWS, Microsoft Azure, or Google Cloud Platform (GCP), you can ignore the documentation below. However, if you prefer not to use a managed Kubernetes cluster on the cloud, there are two major steps you need to complete. First, build Linux VMs for your on-premise Kubernetes cluster. Second, deploy the tools and components required for the Kubernetes control plane (master nodes) and the worker nodes in respective VMs.
Build Linux VMs for Kubernetes cluster
Building on-premise Linux VMs for your Kubernetes cluster is now easier than ever with the SloopStash Linux kit. This kit fully automates the build process of all Linux VMs required for the Kubernetes cluster by integrating with tools like Vagrant, VirtualBox, and VMware. Please use the below documentation to build Linux VMs required for multi-node Kubernetes cluster formation.
Deploy Kubernetes tools inside Linux VMs for cluster formation
Once you have finished building the Linux VMs as mentioned in the documentation above, it’s time to deploy the tools and components required for the Kubernetes control plane (master nodes) and the worker nodes in respective VMs. Currently, SloopStash does not provide open documentation for this process, so please refer to the official Kubernetes documentation to complete it.
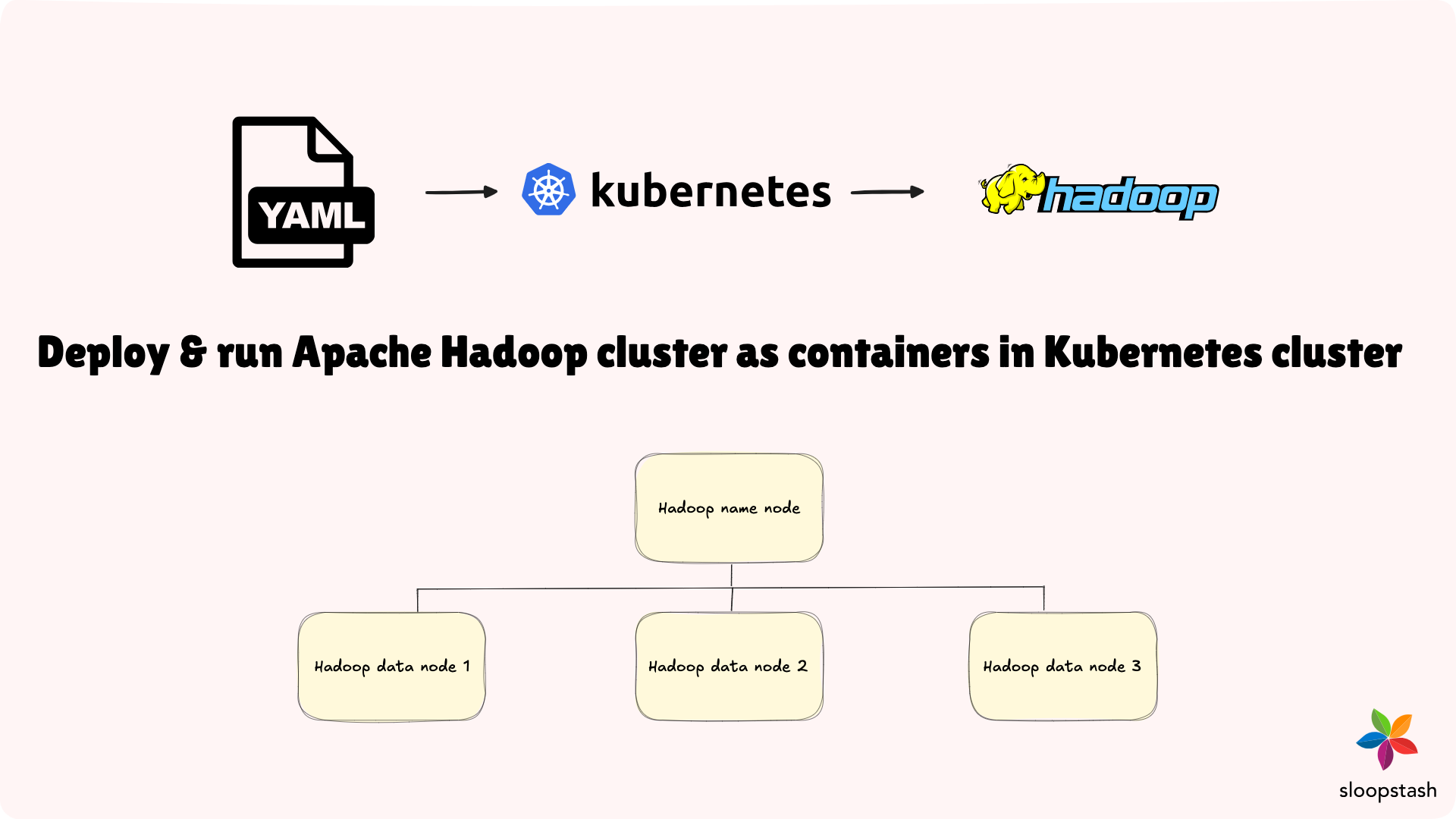
Deploy and run Apache Hadoop cluster in Kubernetes cluster
Once you have a multi-node Kubernetes cluster setup in the cloud or on-premise infrastructure, you can move forward with deploying Apache Hadoop cluster nodes within it. Our SloopStash Kubernetes kit has made deploying and managing a multi-node Hadoop cluster inside a Kubernetes cluster easier than ever.
Getting started with SloopStash Kubernetes kit
We guarantee that the implementation of a multi-node Hadoop cluster will be seamless with our SloopStash Kubernetes kit. This kit includes all the necessary code, configuration, tools, and technical resources for deployment, whether on-premise infrastructure or with cloud service providers like AWS, Microsoft Azure, or GCP. It effortlessly automates and orchestrates the deployment of Hadoop cluster nodes as OCI containers inside the Kubernetes cluster. Please use the below documentation to get started with the SloopStash Kubernetes kit.
Deploy Apache Hadoop cluster inside Kubernetes cluster
To deploy a multi-node Apache Hadoop cluster within a Kubernetes cluster, you need to follow two main steps. First, configure the environment variables that the Kubernetes client requires when executing YAML templates. Second, execute the Kubernetes YAML templates to automate and orchestrate the deployment of Hadoop cluster nodes as OCI containers. Please refer to the documentation below for guidance on deploying and running the Hadoop cluster nodes inside the Kubernetes cluster.
We trust that this blog post on Apache Hadoop and Kubernetes has provided valuable insights. Please reach out to us if you’re looking for tailored solutions or training in these kinds of technologies—whether as an individual or for your organization. We’re here to help you succeed!